句法分析
自然语言的复杂性
1、乔姆斯基体系
非受限文法 –形成递归可枚举语言(可能不可识别)
剩下三种生成的都是递归语言,句子可以被判定。
I型文法–上下文有关法 (CSG)可生成:copy语言 NP完全问题
II 型文法–上下文无关法(CFG)可生成:镜像语言 Polynomial 计算机能够高效计算
III型文法–正规文法(RG)
自然语言不能用RG生成:存在镜像语言
自然语言不能用CFG生成:存在系列交叉依存现象
自然语言属于上下文有关文法,但接近CFG
需要有高效的上下文无关文法的技术
2、线图:保存森林。保留子串的利器,可以在线图中找到很多词法树。
句法分析经典算法
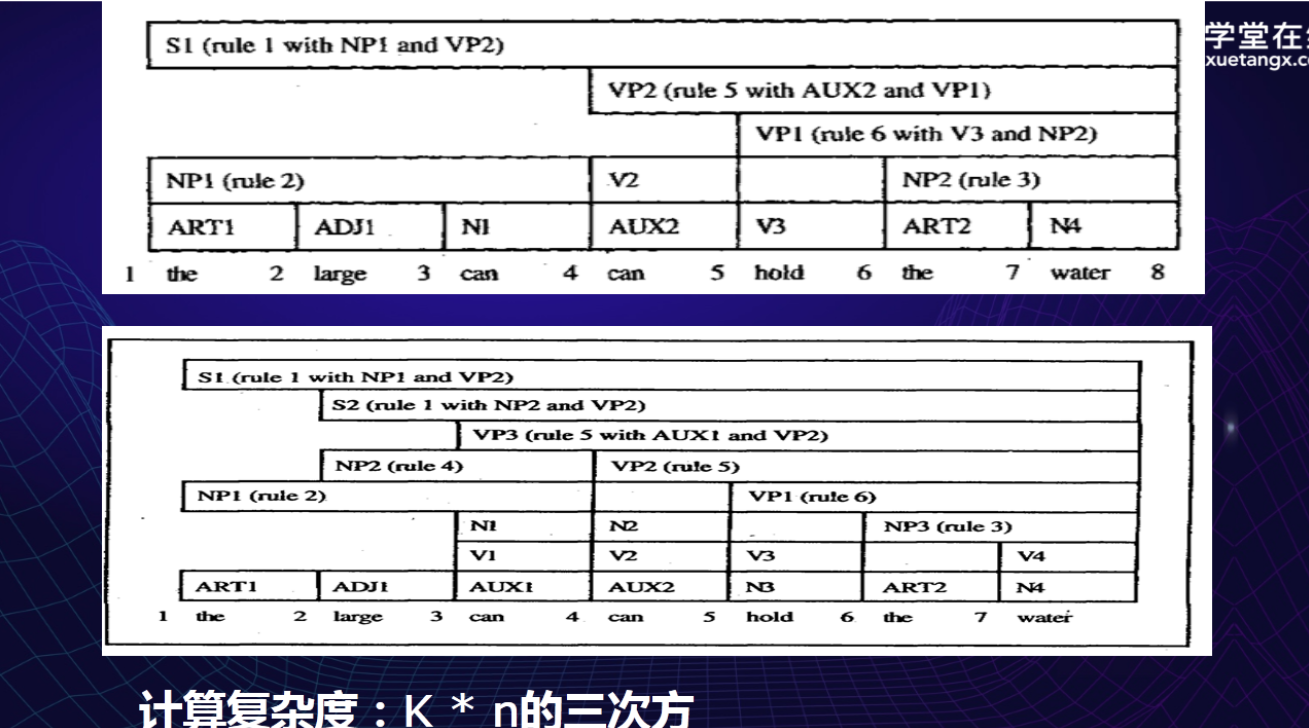
自底向上线图分析
符号:
dot(O):表示左边的符号已经都分析完成,右边的还没有分析。
key:当前分析的成分。
- 如果agenda数据结构为空,扫描当前句子,将扫描到的成分压进agenda
- 从agenda中弹出成分,进行分析,成分中还有位置信息。
- 匹配规则
- 对成分C进行分析:
- 没有到头的句子成分,分析下一个成分
- 到头的句子陈分,将它压入agenda
自顶向下Earley线图分析
先产生一定的预期,即从s出发
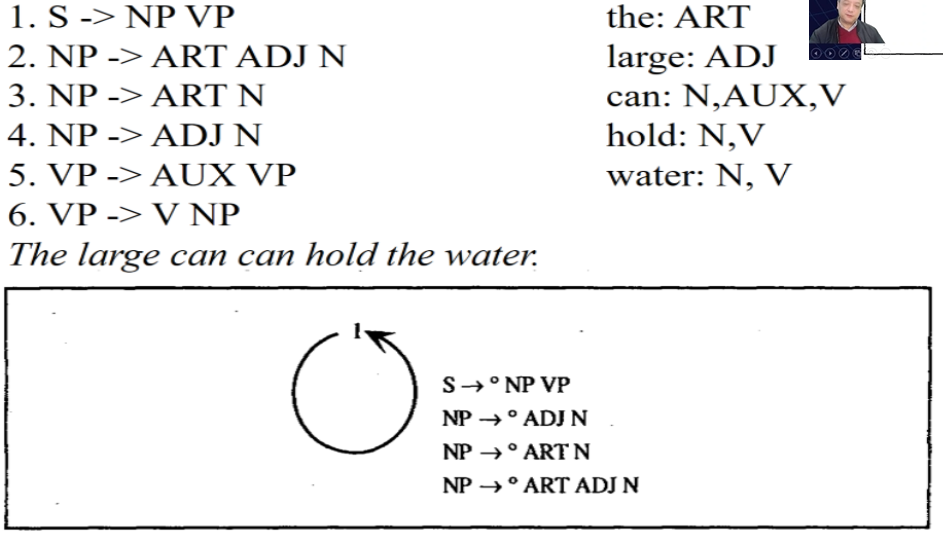
句子来迎合预期,从而达到,通过自顶向下的预期与自底向上的迎合,减少误判以及不合法句子的可能。
所有的非终结符都要往下不断的根据规则展开,直到不能再展开,即对词汇的预期。
对比来看第一张图也就是第二种算法,很多不必要的判断都没有了,提高了算法的效率。
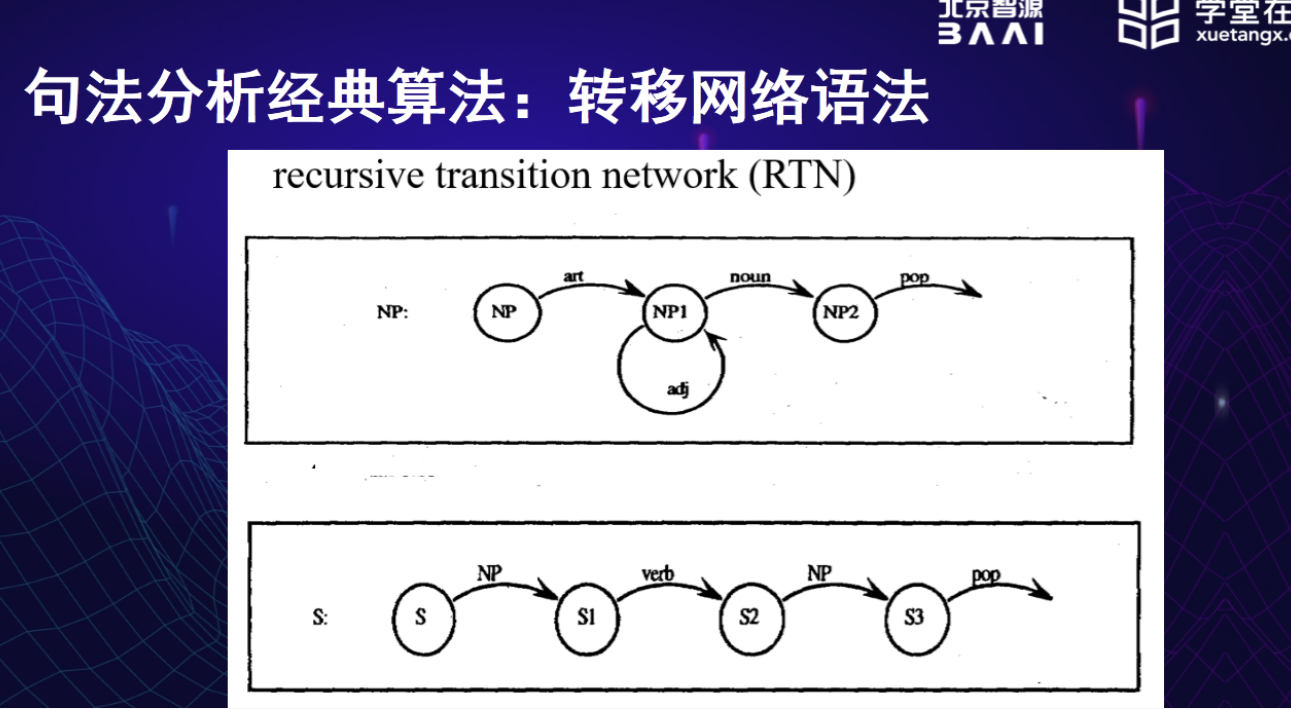
转移网络语法
感觉实质就是自动机
这次自动机里的弧线可以有非终结符,但非终结符也会对应相应的很多自动机
特征系统与扩充语法
主要是处理语法规则问题(?),例如 a men 这是不合法的句子,但是直接用上面的算法判定则是合法的。因而我们需要为词语添加特征,来生成合法的句子。feature暂时理解为,一个单词是一个节点,是由结构体构成,结构体中有很多属性可以代表单词的feature(这些都放在字典中)。句法分析的时候不仅要匹配基本句子结构,也要判断单词的feature检查。
扩充转移网络
ATN—寄存器
概率性上下无关文法
在有树库的基础上,添加已经计算得到的一些概率。可以求得一棵语法树的概率。沿着概率可以加快生成速度,也可提升准确率。概率+词的个性化 == 更快、更精确的结果。
其他问题
基于机器学习的自然语言处理方法,如果能导入句法分析规则,精确度预计可以提高很多。