正在进行有关爬虫的课程项目,在这里把爬虫过程中遇到的问题、报错、感想等都总结一下
2020年4月15日
今天想要实现的功能是爬取网易云用户主页的收藏歌单,歌单的具体内容(标签、介绍)
今天处理的问题有:
(1)链接跳转以及页面过期问题
(2)定位节点以及模拟节点点击问题
(3)节点不存在的错误抛出问题
1、链接跳转即页面过期问题:
想要爬取歌单的更多信息,需要跳转到歌单所在的页面,经过的网页源码的分析可以发现,每个表示歌单节点的内容里可以找到关于该歌单的网页地址,通过browser的get再定位就可以跳转到相应的页面。
关于歌单节点的网页分析如下图所示:
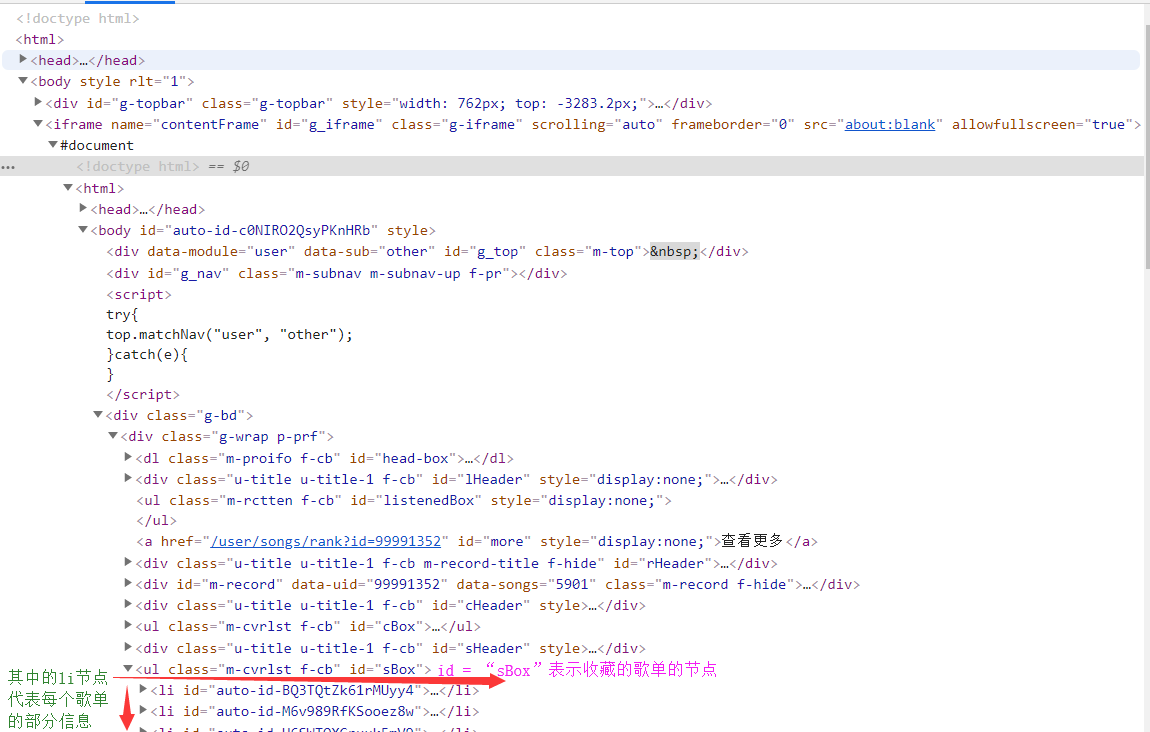
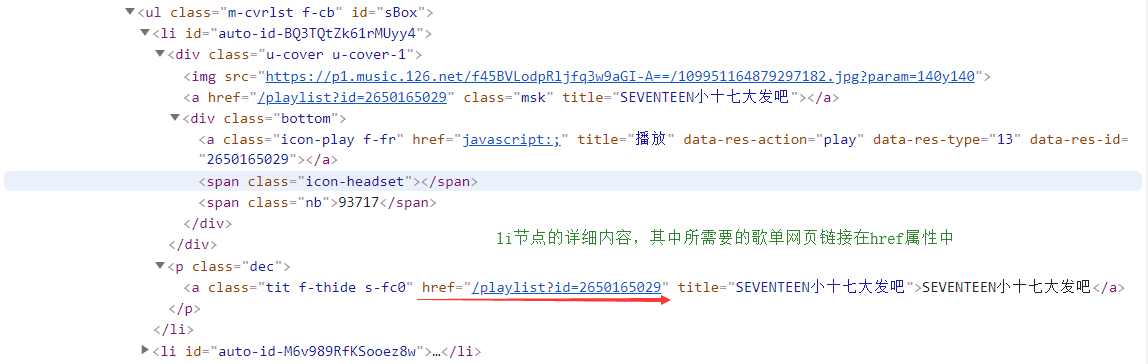
直接利用在用户主页获取的收藏歌单节点的列表lists进行元素遍历,然后依次访问每个歌单的链接,会发现报错: StaleElementReferenceExcepti
1 | selenium.common.exceptions.StaleElementReferenceException: Message: stale eleme |
这个错误表示页面内容的过时,即已经跳转到新的页面了,但是lists连接原本的是旧页面,现在获取的都是新页面里面的li的内容,自然找不到想要的内容(自己理解的原理,不一定正确),因而过时错误。
解决方法:在转换页面前,将lists中想要的li节点的属性href重新保存在一个新的列表里,然后遍历新的列表即可。
相关代码:
1 | '''lists是之前函数获取的li节点的合集列表''' |
2、定位节点以及节点点击问题
问题引入:歌单详细信息的介绍内容经常需要鼠标点击“展开”按钮后,里面所有的内容才能完全的显示出来被爬虫获取,因而需要获取“展开”节点并模拟点击该节点。
网页结构如图所示: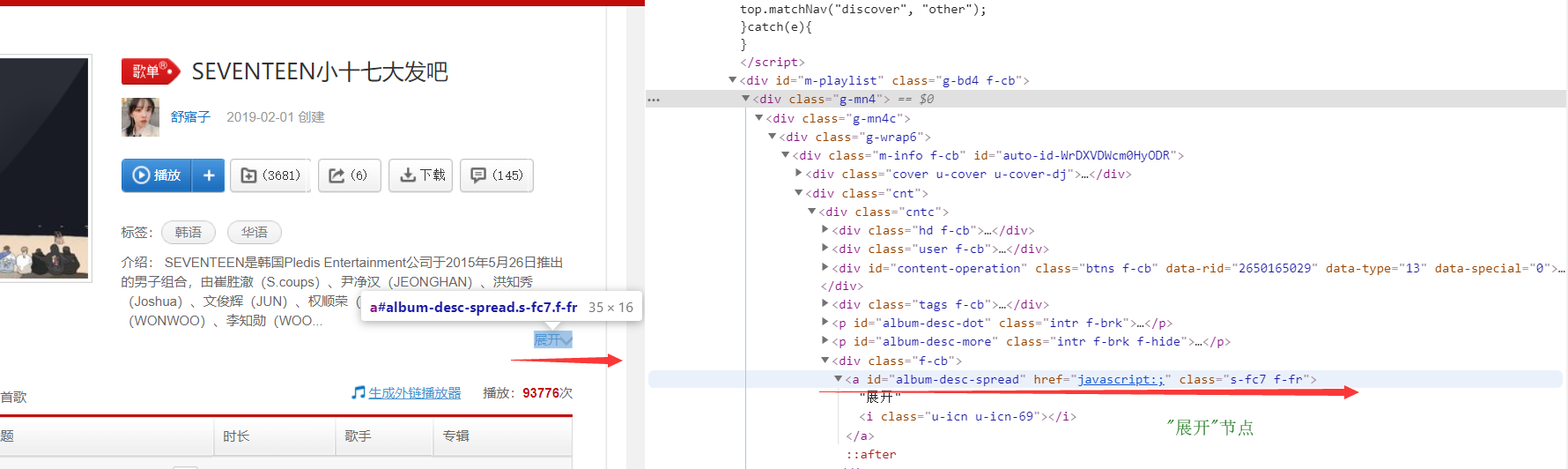
定位节点即通过find相关函数,输入节点特有属性值,即可找到节点,目前更常用的是ccs选择器,觉得一目了然,比较简单。
节点点击:简单版:获取的节点(WebElement类型).click()
(更难的还在探索过程中……)
出现的问题:
1 | WebDriverException: Message: Element is not clickable at point (918, 13). Other element would receive the click: <div class="xxx"></div> |
这个错误目前了解的不是很多,大体的意思是点击这个button的时候,这个单击事件被上层的div给接收了……说明div覆盖在这个button上面。上面的div可能也存在相应的节点,导致点击事件被截获。
解决方法 :我是再去找节点的特殊性,使节点只能定位到我想操作的那一个节点上,该节点的文本内容只有“展开”,而其他节点可能是“展开XXX”,借助str中的方法endswith(),判断点的后缀是否是“展开”来定位到该节点并click()打开
相关代码:
1 | '''判断是否有需要展开的内容''' |
3、节点不存在的错误抛出问题
问题引入:不同的歌单有不同的属性。有的歌单可能标签+介绍+介绍展开三者节点都存在,有的可能只存在一个或两个,有的甚至一个节点都不存在。如图所示: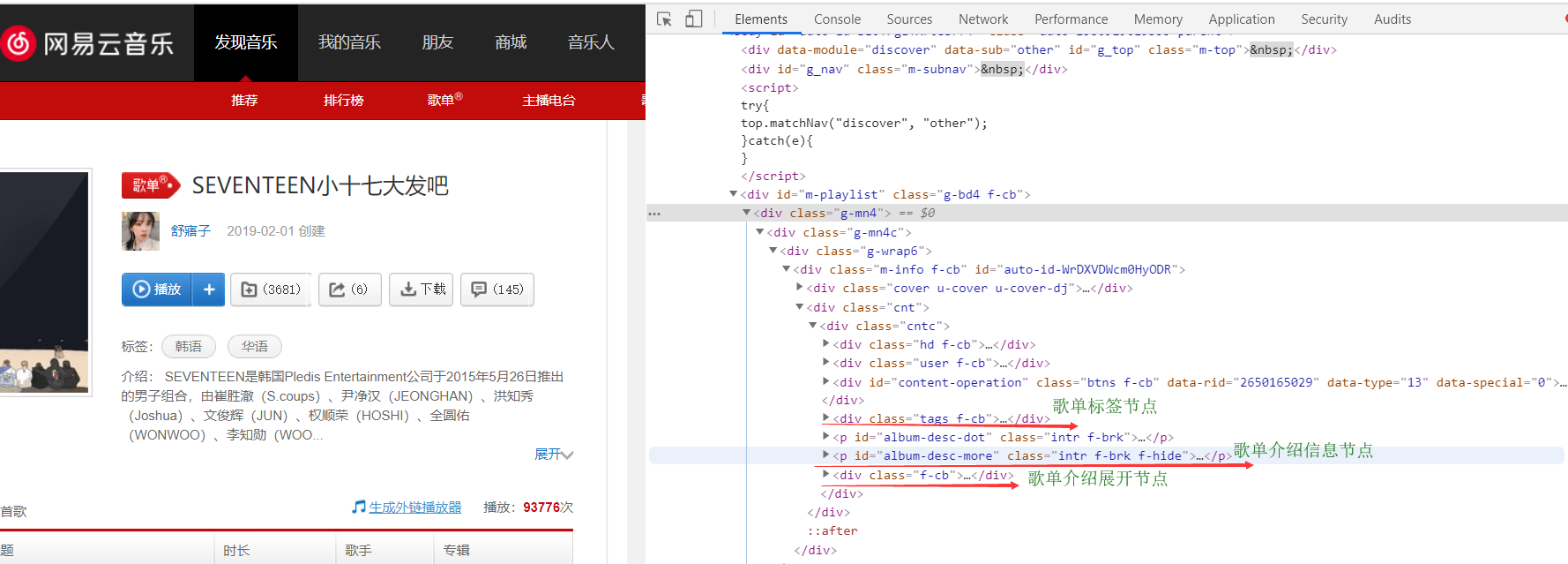
三种节点都有的歌单
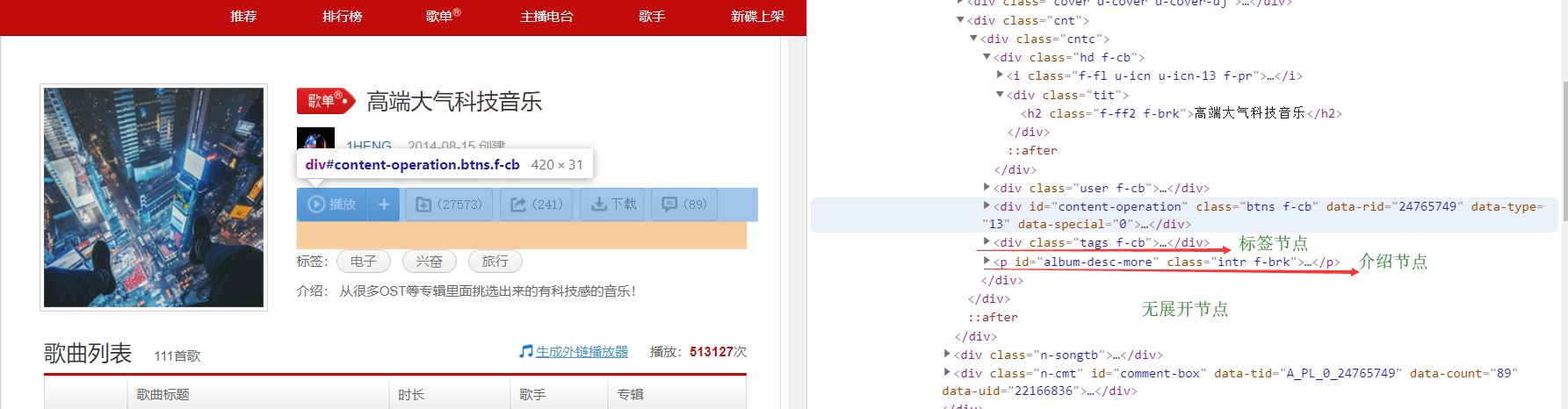
有两种节点的歌单
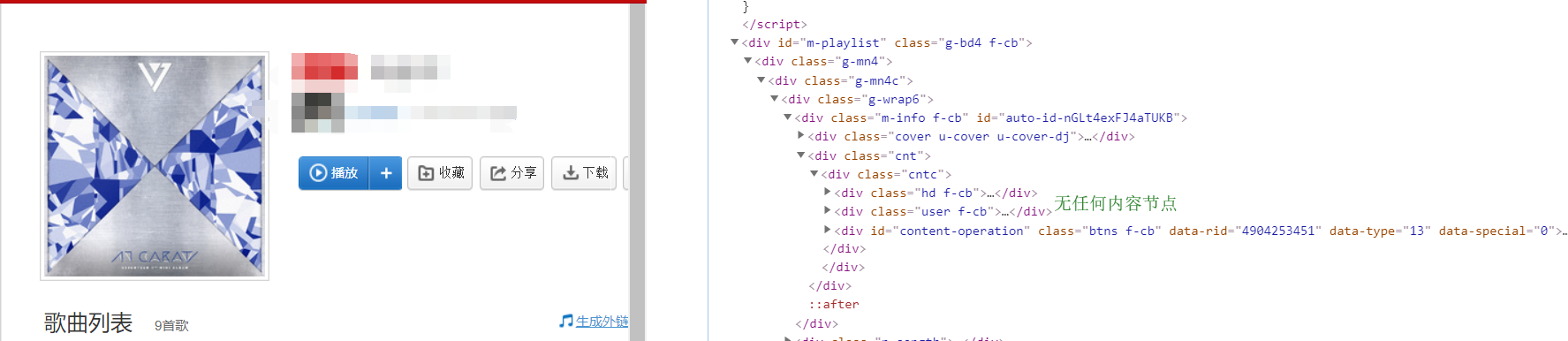
一个节点都没有的歌单
如果获取不存在的节点会报错:
1 | selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: |
解决方法:设置异常抛出,没找到节点不执行任何行为,找到了则输出相关内容,三个节点都要判断。
相关代码:
1 | '''输出介绍信息''' |
注意:一开始会出现NameError: name ‘NoSuchElementException’ is not defined的报错,即python内部没有相关错误类,通过引入即可
1 | from selenium.common.exceptions import NoSuchElementException |