Deep Learning
bilbil:P12、P14
三步走:
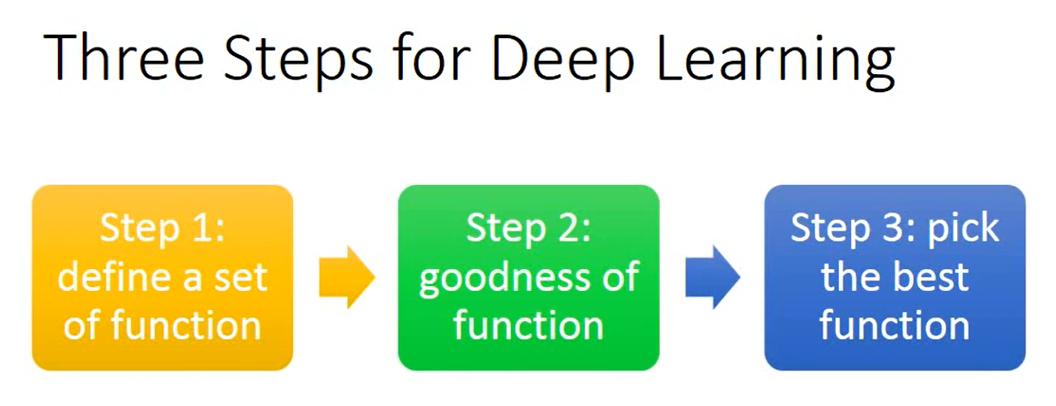
- step1:确定网络的链接方式,确定网络结构一种连接方式可以对应一个function set
step 1
链接方式介绍:
- fully connect feedforward network
(全连接前馈网络)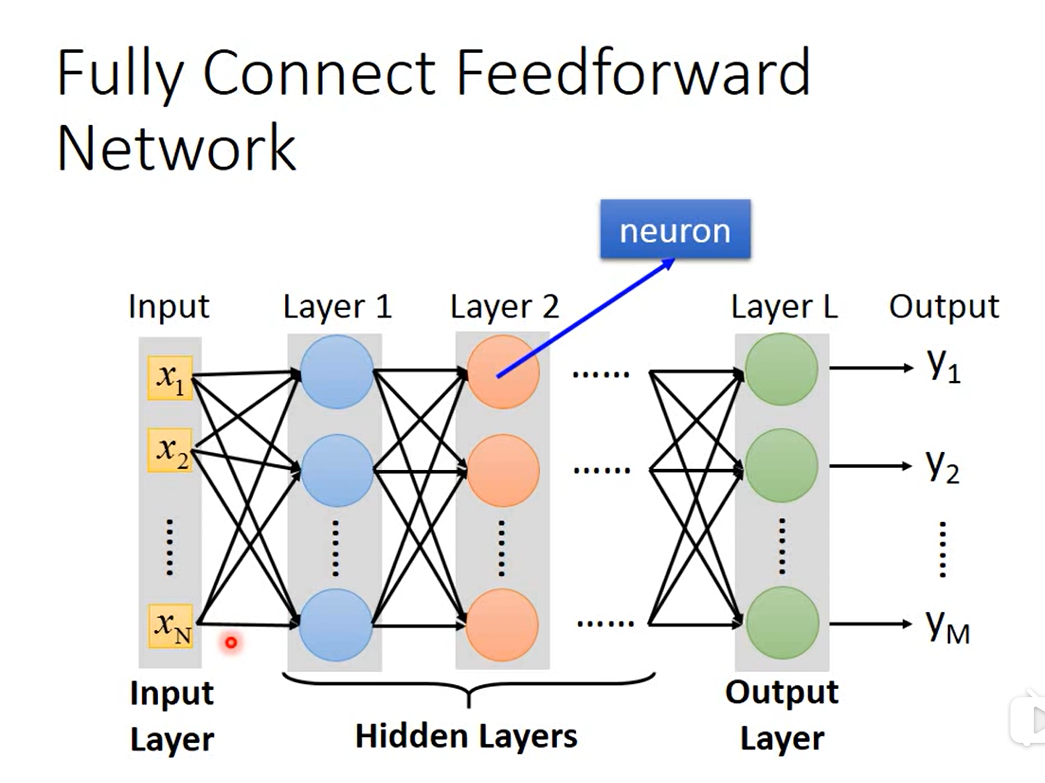
特点:
input传递是从低级的layer向高级的layer传递,所以是forward
对于低级layer的每一个神经元(neuron)得到的对应的output结果,要传给下一层的每一个neuron,这则是所谓的Fully,全连接。
Deep = many hidden layers(很多的隐藏层)
一个layer的运算可以通过一个矩阵表示。整个全连接网络可以用矩阵的计算表示,好处在于矩阵运算可以通过GPU加速。
里面的正方形是矩阵
长方形也是,但同时也是一个向量。hidden layers中,主要是将原始的feature进行一定的变换,使得在最后的output层可以比较容易的得到好的模型
Q:如何决定层数、决定每层的神经元数、决定链接方式?(好的结构里面存在好的function)
A:直觉、经验、尝试等
step 2
定义function的好坏,利用training data,同逻辑回归的方式。利用梯度下降的方式,最小化Loss函数,得到相应的function和它的参数集。
step 3
选择好的function
WHY DEEP?
问题:为什么是增加层数layer,而不是在中间层不断增加神经元?实质是在参数相同的情况下,层数更多的(thin)网络结构表现更好(deep),还是一层内神经元更多的(fat)网络结构表现更好?
结果表明,层数更多比单单一层更多神经元的结构表现效果好很多。
原因:deep是在模块化网络。模块化的好处是能够减少冗余、重复利用。对于deep learning 来讲, 效果则是可以用比较少的data也能到的好的模型。底层的layer相当于basic classifier,高层的模型建立都是基于底层。模块化是机器自动从data学习而来。(?)
举例
语音中的模块化运用
语音辨识初步过程
1、取语音音频,每次截取一小段并将其归类为不同的state
2、每一个state要进行分类,分给不同的phoneme(发音单位)(这里就用到了分类)
3、其中因为phoneme与前后的发音有关系,又将相同的phoneme分成不同的tri类,然后每个tri类又分为三份,理论上每一份对应一个model。
问题来了,这样的话model太多了,数据量根本训练不出好的模型。
发现:不同的“每一份”可以共用相同的分布模型。 —- 模块化
其实phoneme之间客观上也是有关系的。
deep learning做法:
input:acoustic feature
output:probability of each state
所有的states共用同一个DNN(深度神经网络)
先研究发音方式(模块化),然后进行发音分类
DNN的好处(模块化)
- 使用参数更有效率
普遍性定理是,一层layer就可以将各种参数转换成想要的维度的输出,一层网络就可以表示所有的function,但是这样矮胖的网络结构是没有效率的。深层网络是比较有效率的。
逻辑电路类比
1、两层逻辑电路可以表示任何的boolean function。
2、但没有人会这么做,因为没有效率,多层结构比较有效率,可以用比较少的逻辑门。
更少的逻辑门象征更少的参数需要计算,即降低overfitting的概率
逻辑电路中的道理和和深度神经网络是一样的
最终的效果是,较少的data可以训练出类似的结果
END TO END learning
只给机器input 与 output,让其自己进行学习训练。
理论上的想法:
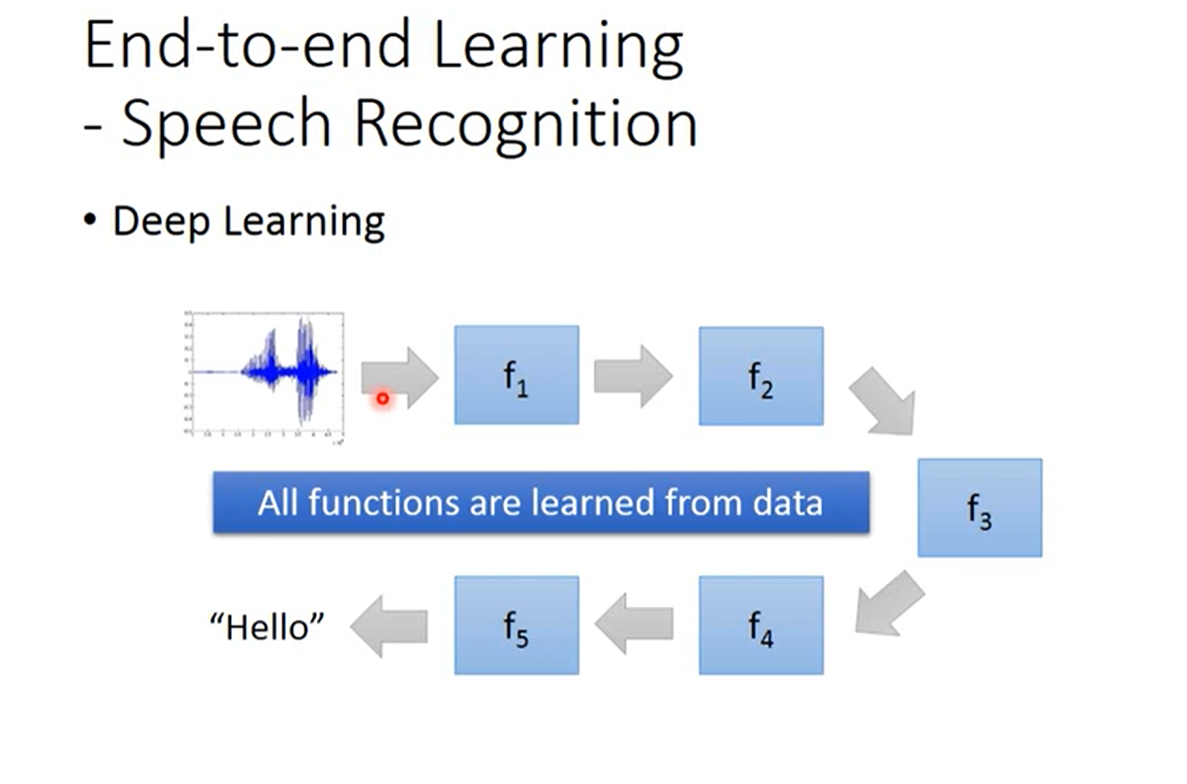
其中的function不会经过人工加工,不通过人工的之前的研究、经验,直接丢给机器,让其自主进行数据分析,功能完善。后来通过谷歌的研究发现,机器的再自主学习做出的最终结果与人类干预差不多,不会比人类知识干预要好,分析发现机器所做的学习和人类通过认知进行的数据干预处理是类似的。
Deep learning的其他好处
- 有很多复杂的task,可能有的输入很类似,但是输出的结果应当是不同的;有的输入很不一样,但是输出的结果应该是相同的。想要达到这种效果,就需要让数据经过很多层次的转换。deep learning就可以实现这样的事情。