Structured Learning 结构化学习
对应视频BV13x411v7US P32
1、应用举例
- 语音辨识
- 翻译
- 句法分析 syntactic parsing
- 对象检测 object detection
等等
Unified Framework 统一框架
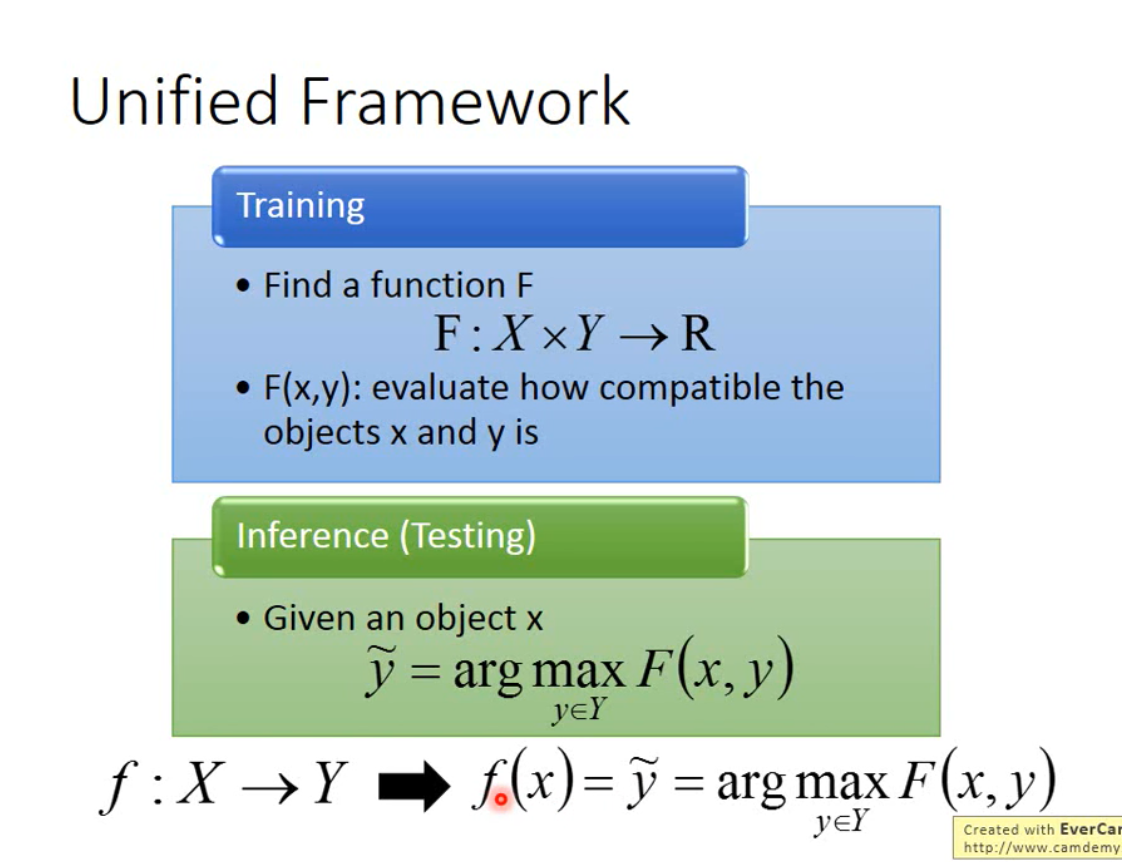
主要分为training训练和inference推断两步:
- training部分目的是找到F(X,Y),训练数据x与y都是输入值,F的输出值是一个评判值,当x与y越匹配的时候,F得到的输出值越高,F是评估x与y匹配的一个函数。
- inference 推断:将未知的X值输入,然后穷举所有可能的Y,将X与Y带入训练好的F函数中,使得F函数值最高的Y,即我们要找的输出。
以对象检测为例
输入:一张图像
输出:想要寻找的对象所在的位置
Training 训练部分
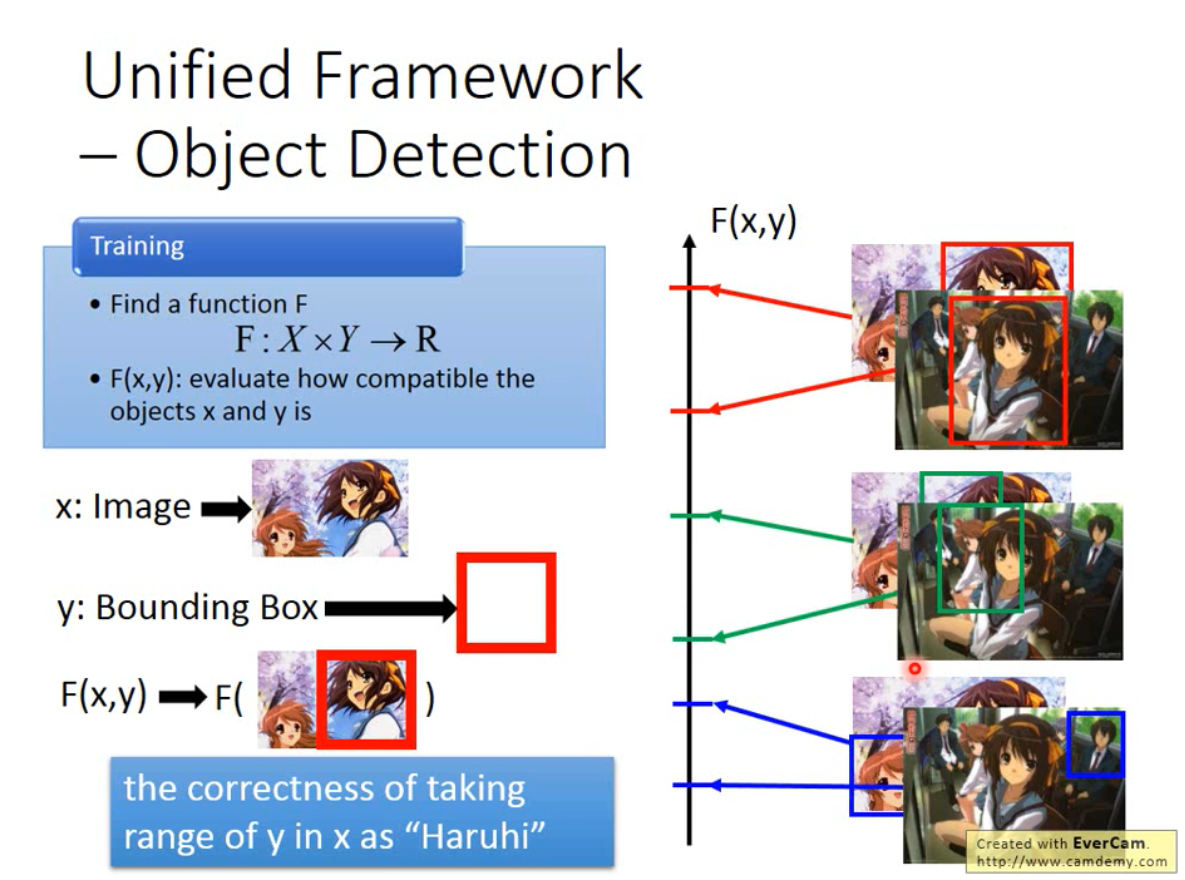
如上图,将图像X与框框Y随机匹配,当Y框对了对象的时候,F的值最高,当Y框了部分对象的时候,F的值偏低,当Y完全没有框对对象时,F的值最低。我们要训练的就是这样的一个F函数。
Testing
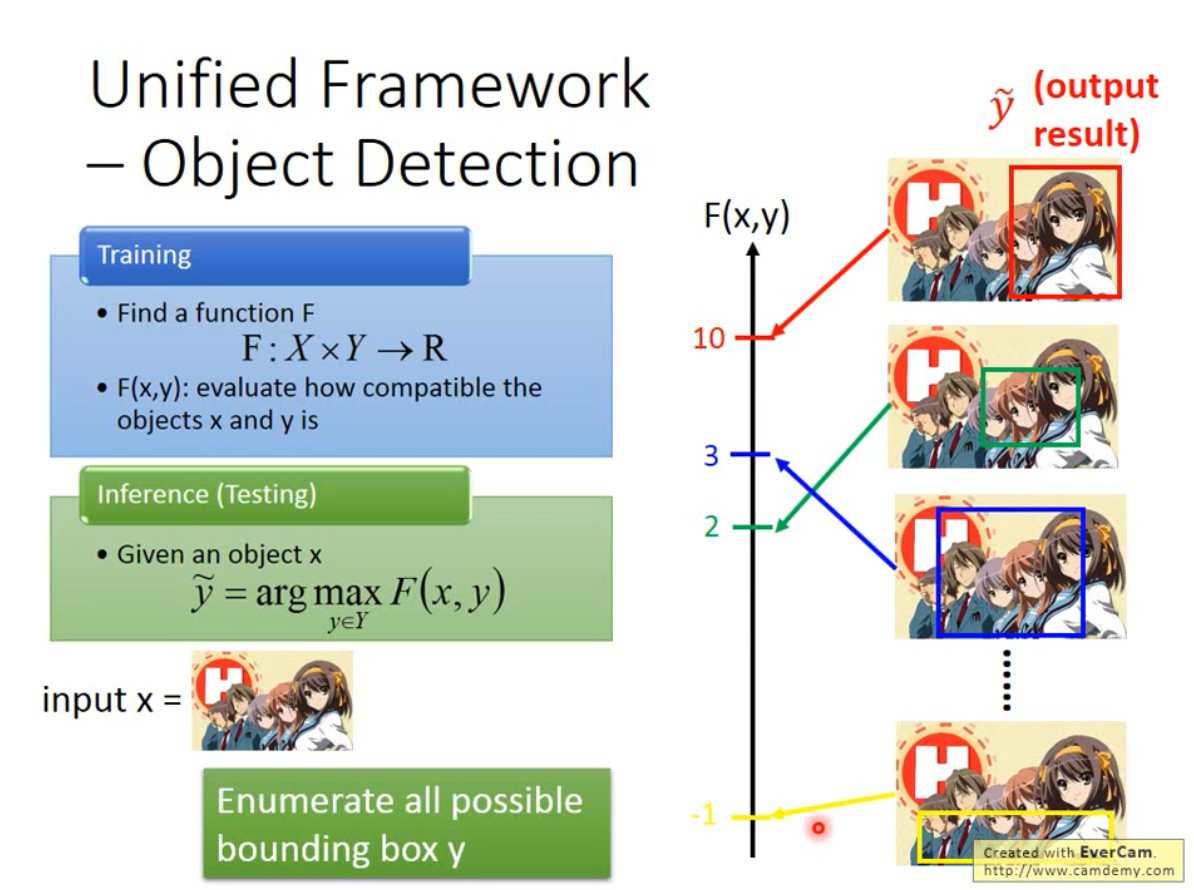
输入没有接触过的图像x,穷举所有的框框Y,依次与X一起放入训练好的F函数,进行匹配,当F越高,说明Y框框正确的可能性越大(或者框出的部分中,正确的部分占比越大),取使得F最大的Y,就是我们需要的输出。
统一框架中的三大问题以及解决方法
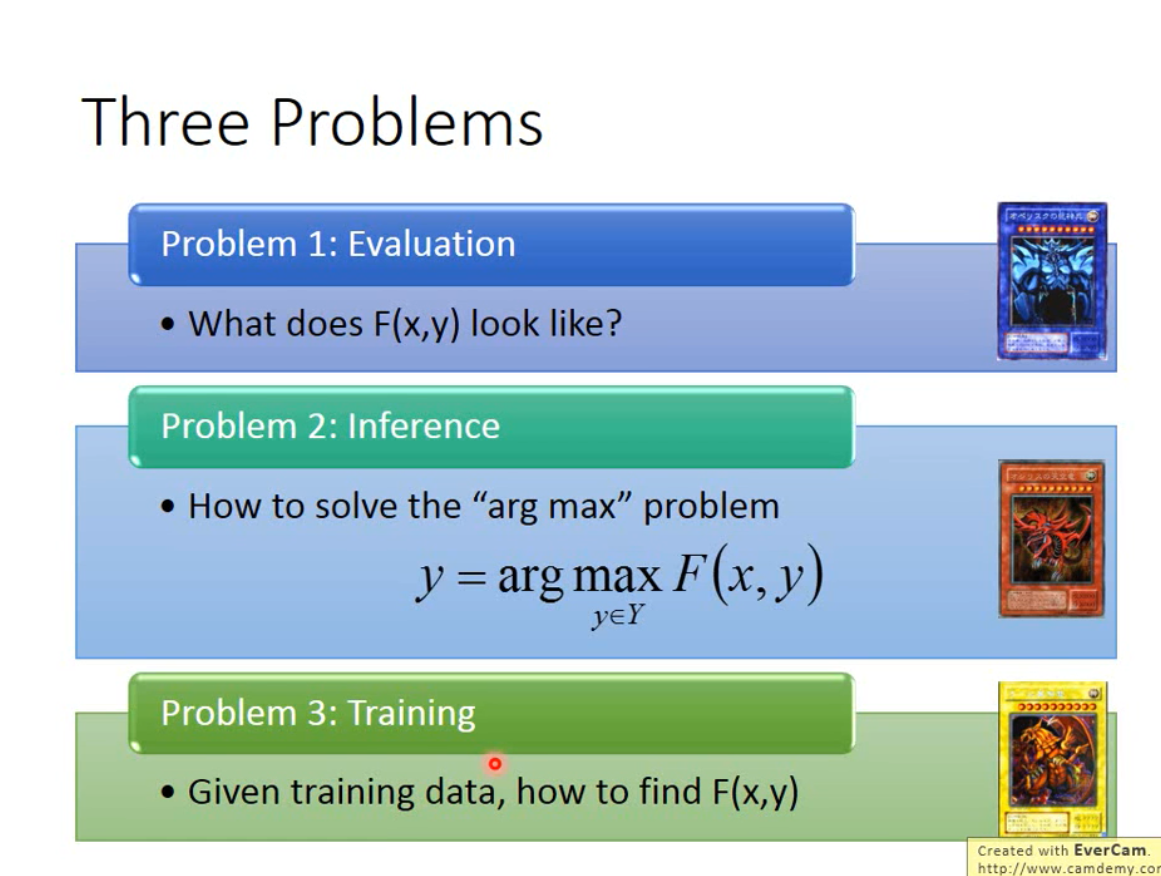
以结构化线性模型为例
Problem-1:F函数是一个什么样的函数

Problem-2:怎么做,才能穷举所有的Y,得到使得F函数最大值的Y,即如何解决最大化问题
假设问题已经被解决了
Problem-3:如何通过训练找到F函数
由第一个问题可得,解决这个问题的实质是,找到满足什么样的条件的W向量。满足的条件如图的黄色部分所示:

即:w与正确的(x,y)对的特征做内积的值,都会大于任意的W与其他的(x,y)对做内积的值。
举例说明: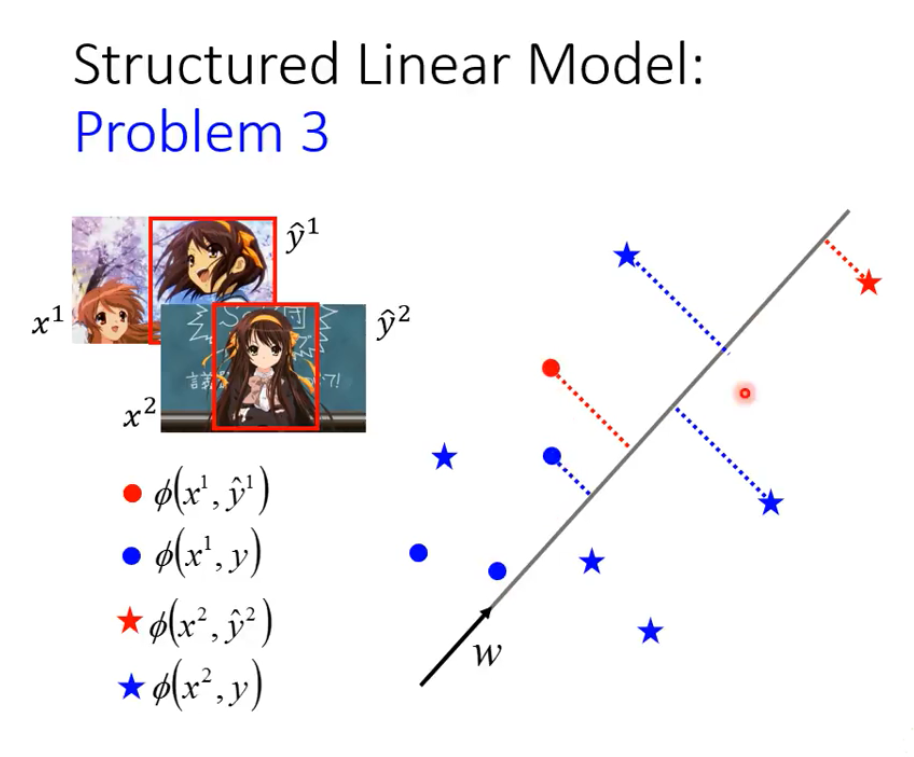
其中红色的点是正确的点(training data),蓝色的点是任意点。
根据内积的几何意义,也就是将每一个(x,y)对,投影在W向量方向上,要满足所有红色的同类型的点,在W向量方向上的值是最大的。
需要根据training data训练出这样的W向量
解决方案演算法
主要步骤:
- 初始化W为0
- 对于每一对training data,穷举所有的Y,然后将对应的(x,y)特征与目前的W做内积,选出使得这个内积最大的y’。(这个其实是第二个问题,现在我们假设了第二个问题已经被解决了,也就是我们可以计算出最大值,以及找到对应的y)
- 如果y’ != 正确的y,按照图片上的式子更新W的值,再进入训话计算。
- 直到对于训练集中所有的(x,y)对,使得W与特征的内积最大的就是正确的y的时候,W不再更新,跳出循环,训练完成。