词法及语言模型
词表示
是翻译词中的符号成为机器可以理解的语义的过程。能让计算机理解每个词背后的meaning,实现对词的语义信息的表示。
应用:计算词之间的相似度,发现词之间的关系。
利用近义词和上位词表示的缺陷、利用词典进行词义表示的缺陷:依旧会丧失词义的细节信息;人工编撰的字典更新比较慢,对词汇新的词义很难捕捉到;也会包含一定的人的主观感受;大量的人力
one-hot representation
在计算机里给每一个词赋予一个独一无二的id,利用长度为整个词典的向量进行词表示,除了id位为1,其他位都为0。
最常用的是,对整篇文档进行表示,形成关于文档的高效表示,可以用来计算两个文档之间的相似度。—词袋模型
存在问题: 没有办法表示和衡量任意两个词之间的相似度。词的表示之间的都是正交的。没有办法保留相似度之间的信息,假设每个词都是独立的。
Represent Word by Context
You shell know the word by the company it keeps
词的表示和其所在的上下文有密切的关系。利用一个词的上下文的词来表示这个词。
Co-Occurrence Counts
还是用一个词典长度的vector来表示单词,这里用大量的文本中,出现在这个中心词周围的单词的次数(count-based),上下文词的分布(distribution)作为表示这个中心词的向量。
window短:获得更多句法信息
window长:获得更多语义信息
Term-term matrix:词和词之间同线的矩阵
如下图,生成的矩阵行和列都是单词的长度,eg: i和like在这三句话(语料信息)中同现两次(出现在同一篇文章中),所以组成的矩阵中,matrix[i][like] = 2 (m = 2?)

Term-Document Matrix:词和文章形成的矩阵
行和列分别是单词和特定文章,每一列可以用该列生成vector表示当前文章。

相似度计算方法:(1)计算点积(相同维度相乘再相加) (2)余弦相似度:相当于做了一个归一化,点积除以向量的长度。
问题:(1)向量的size随着词汇量的变大而变大。存储等都是问题(2)低频的词汇,向量很稀疏,计算的精确度下降。
分布式词表示
1、语言模型
做什么:
- 计算一个文字序列,组成语言的概率有多少。
- 知道序列的前半部分,能够预测出下一个字符是什么的概率。

假设:wn出现的概率,仅有w1……wn-1决定。
N-gram Model
因为如果将一个词前面出现的词全部计算来计算其概率,算法复杂度太大。为了解决这一缺陷,会选择限制选择前面词的数量(比如只利用前2-3个词来计算当前位置的词出现的概率)。即某个词条件概率只依赖于其前面有限个词的概率。
问题:(1)因为是近似,所以会存在着不准确性。(2)不能够很好的捕捉词之间的相似性。
Neural Language Model
过程:
- 每个词用one hot表示组成一个矩阵
- 通过输入的句子序列,将在一起的两个词vector取出,拼接到一起。
- 通过一个激发函数
- 通过一个映射函数(机器学习得到参数矩阵)
- 通过softmax函数,将值归一化,这样得到的向量里,每一个维度代表着这一维的词是接在后面的可能性的大小。

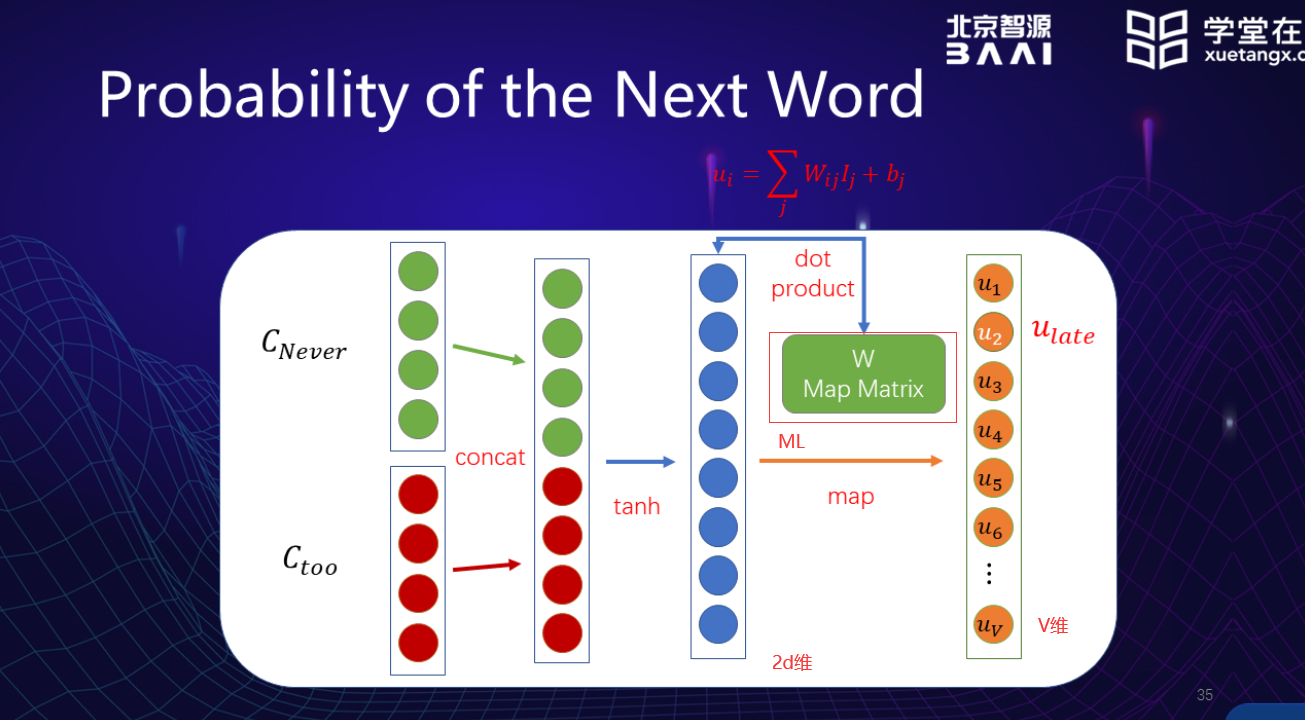
loss function:交叉熵

总结:

缺陷:(1)太多的参数 (2)太多的计算
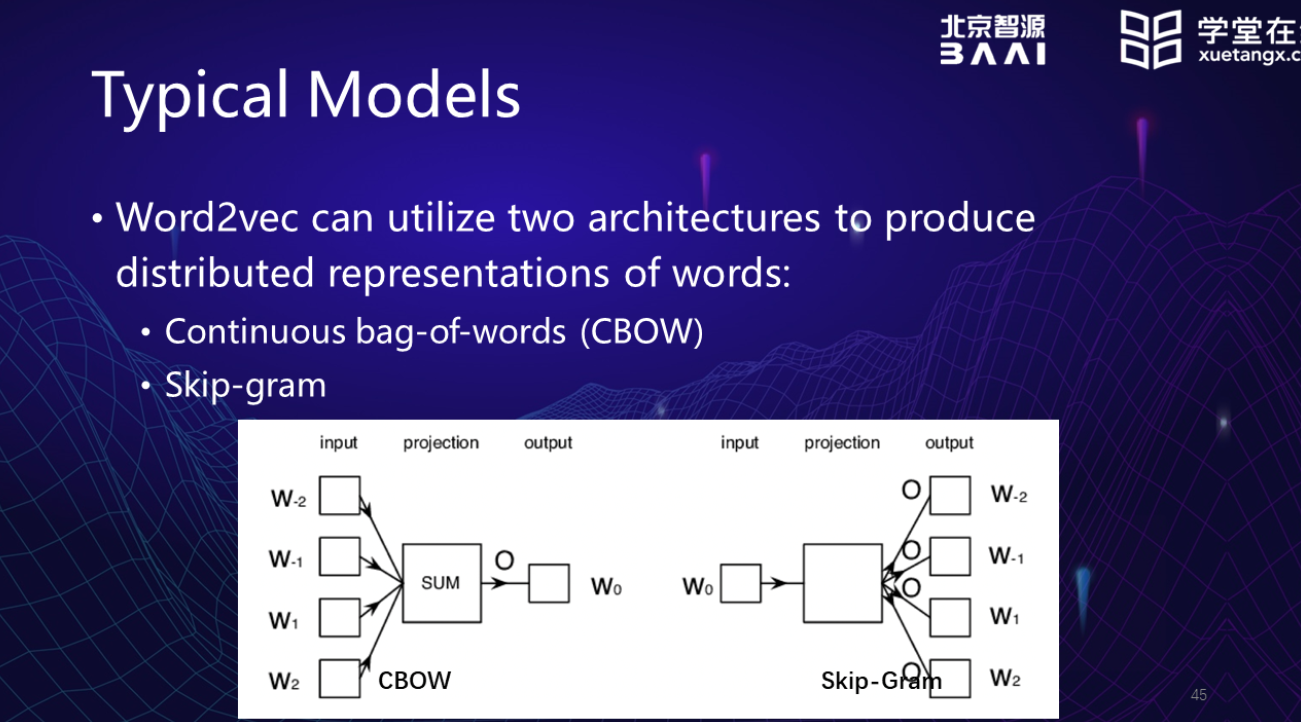
Word2Vec
CBOW: input:上下文 output:w0预测中心词
Skip-Ggram: input: W0中心词 output:上下文的词汇
CBOW
用上下文的词来预测中心词
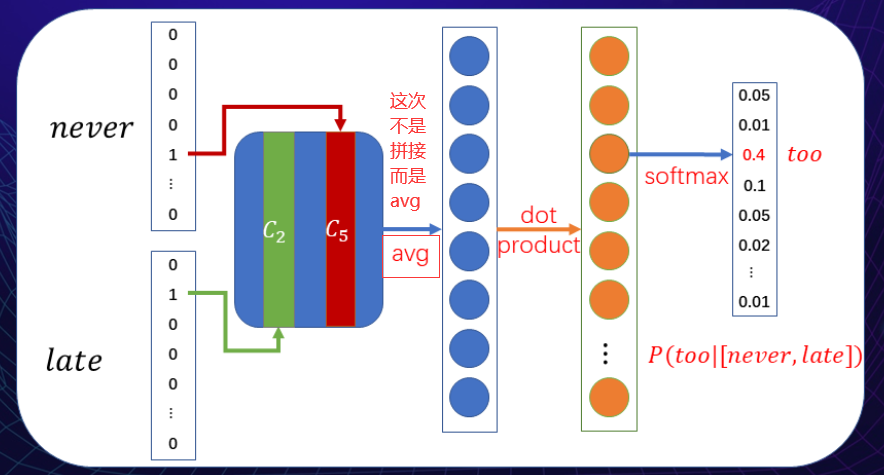
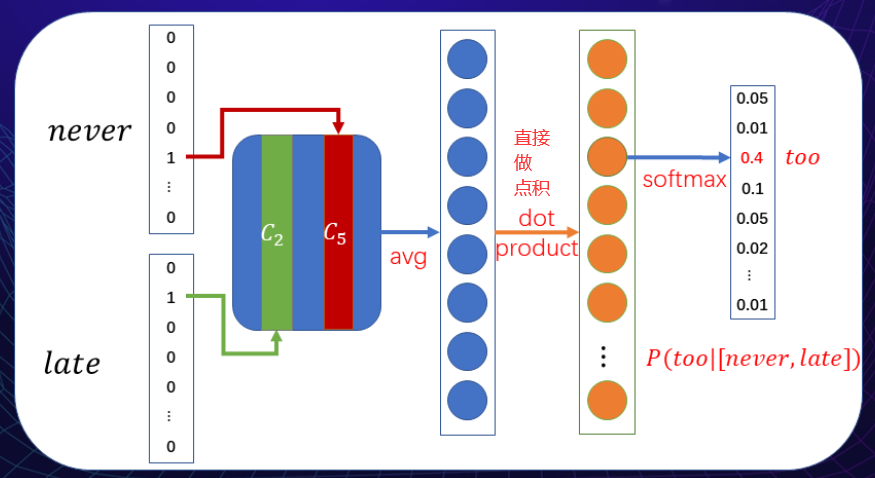
问题: 过于依靠上下文来表示词义,如果两个词上下文相同,就会得到很相似的词向量表示,但可能这两个词并没有那么高的相似度。
skip-gram
中心词预测每一个上下文的词,分别预测其可能的上下文
整体

- 最复杂的步骤是计算softmax来形成概率向量
- loss-function也是利用交叉熵,也利用各种优化器来反向传播
问题: softmax的计算非常复杂,每个词都要算
两个改进方法:
Negative sampling 负例取样
不是将每个词都计算,而是针对某一个中心词,只取一定量的负例(也就是不正确的其他词)来进行计算,只要保证负例与正例之间的距离足够大就可以。

Hierarchical softmax
根据单词的频度,组装成哈夫曼树。计算softmax不需要再计算全部,沿着树的路径来算即可,也可以提高效率