Semi-supervised Learning 半监督学习
对应视频BV13x411v7US P23
基本介绍
- 半监督学习的特点是,训练数据中存在一部分没有标记的数据,且数据量一般比标记后的数据要大。
- 为什么使用半监督学习?因为我们更多的数据是没有标记的,如果能有效地利用这些未标记数据可以将模型训练的更好,但是这方面,精确的“假设”起很重要的作用。
generative model 生成模型
1、初始化模型参数后,计算每一个没有标记数据的后验概率,看看是输入哪一类别。
2、利用已经得到的数据,再次更新模型的参数(协方差、均值等)
3、反复第一步第二步,理论上模型最后会收敛。
self-training
Entropy-based Regularization
1、我们通过标记数据的得到的模型,用来计算未标记的数据,这时候得到的对应的y是一些分布(distribution),这个分布越偏向某一类是越好的分布。判断分布的好坏可以利用信息熵来计算。信息熵为0是好的,信息熵很大的是不好的。

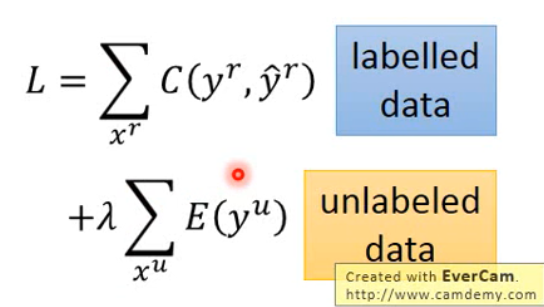
2、根据这个假设可以重新设置loss函数。
全新的loss函数由两部分组成:第一部分对应的是labelled data,计算模型中的y值和实际的y值的距离;第二部分对应的是unlabeled data,计算信息熵让其最小化。
Smoothness Assumption(平滑的假设)
假设:对于相似的X,Y值假设是一样的
详细:1、x是不平均的,在某些地方集中,在某些地方分散。
2、当x1,x2在高密度的地方是接近的,y1与y2假设是一样的。
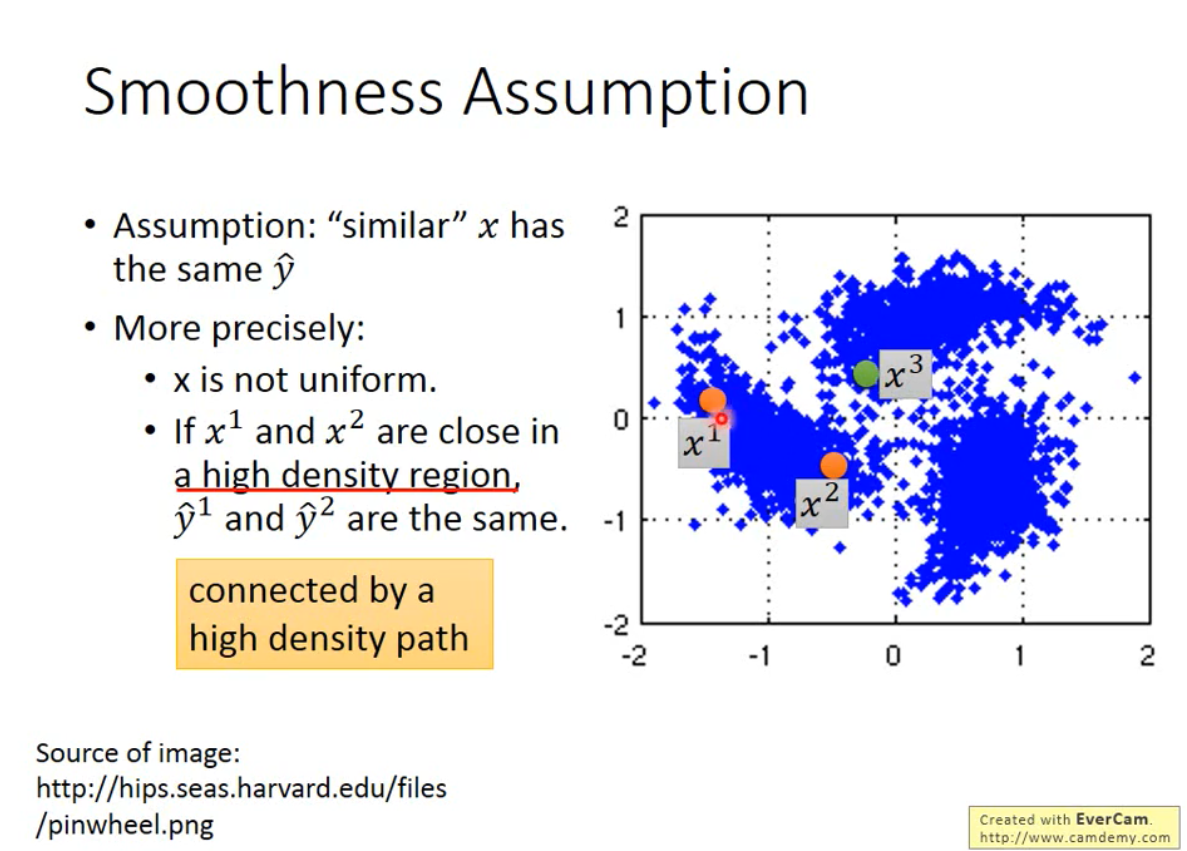
x1,x2更偏向于有相同的y。
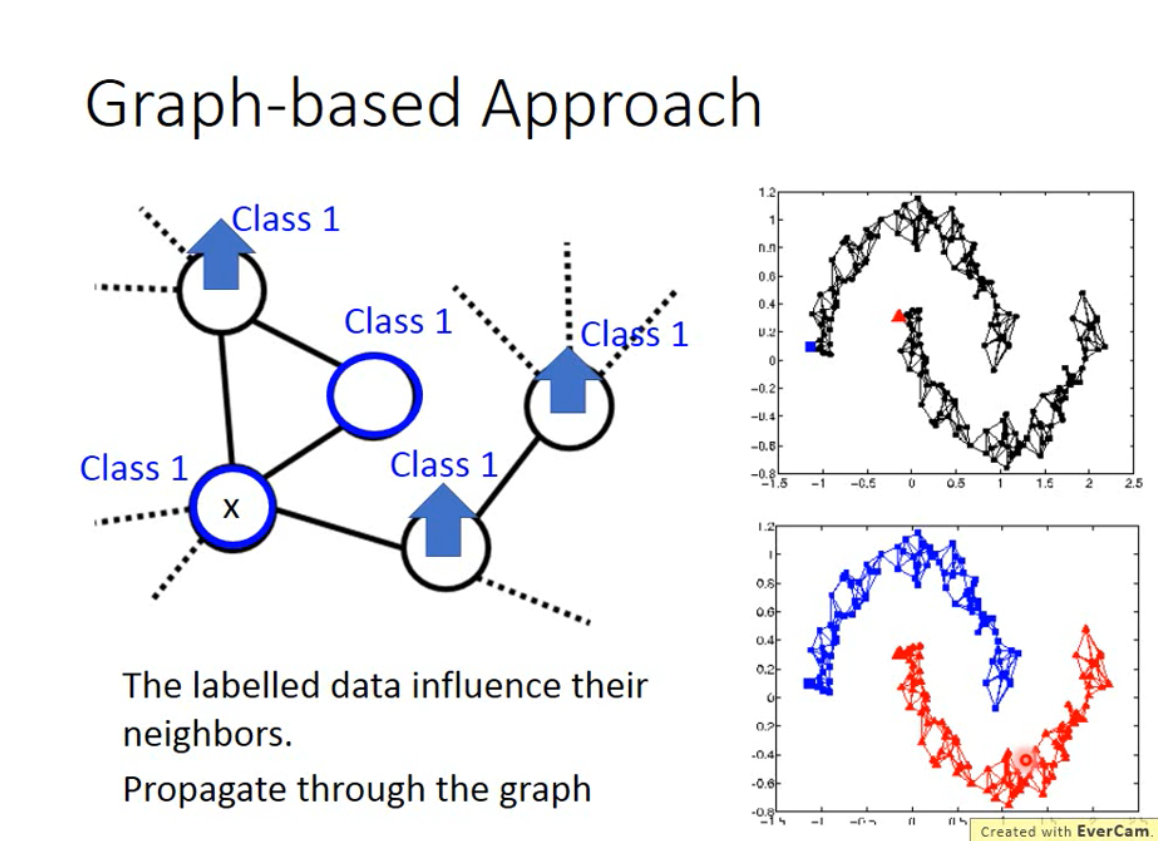
Graph-based Approach
通过图的连通性,反映两个点之间的相似性。
- 将数据用图的形式表示出来
- labelled data会影响自身连接的邻居值。
- 被影响的数据点,也具有影响性,可以影响其他与其相连的点,即使这个点没有和任何的labelled data相连。
定量表示smoothness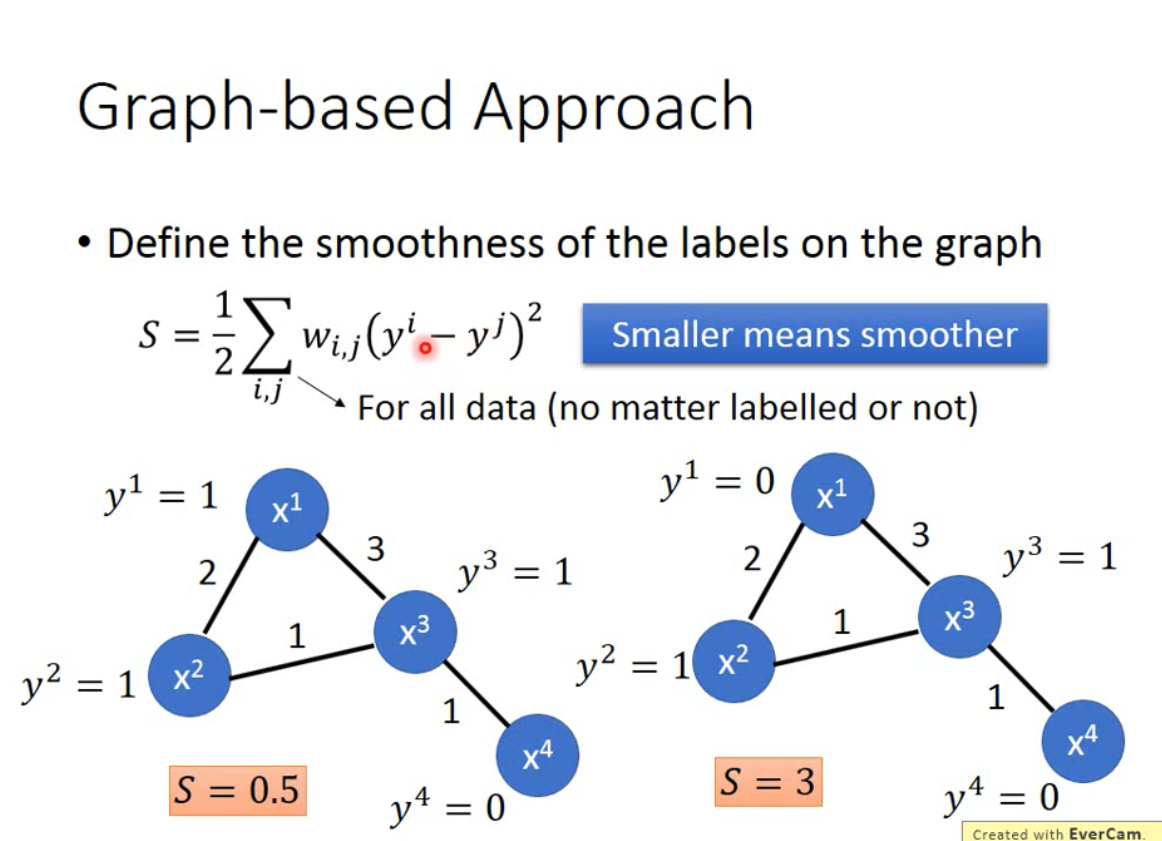
s的值越小,表示越光滑
根据该假设又可以重新定义Loss函数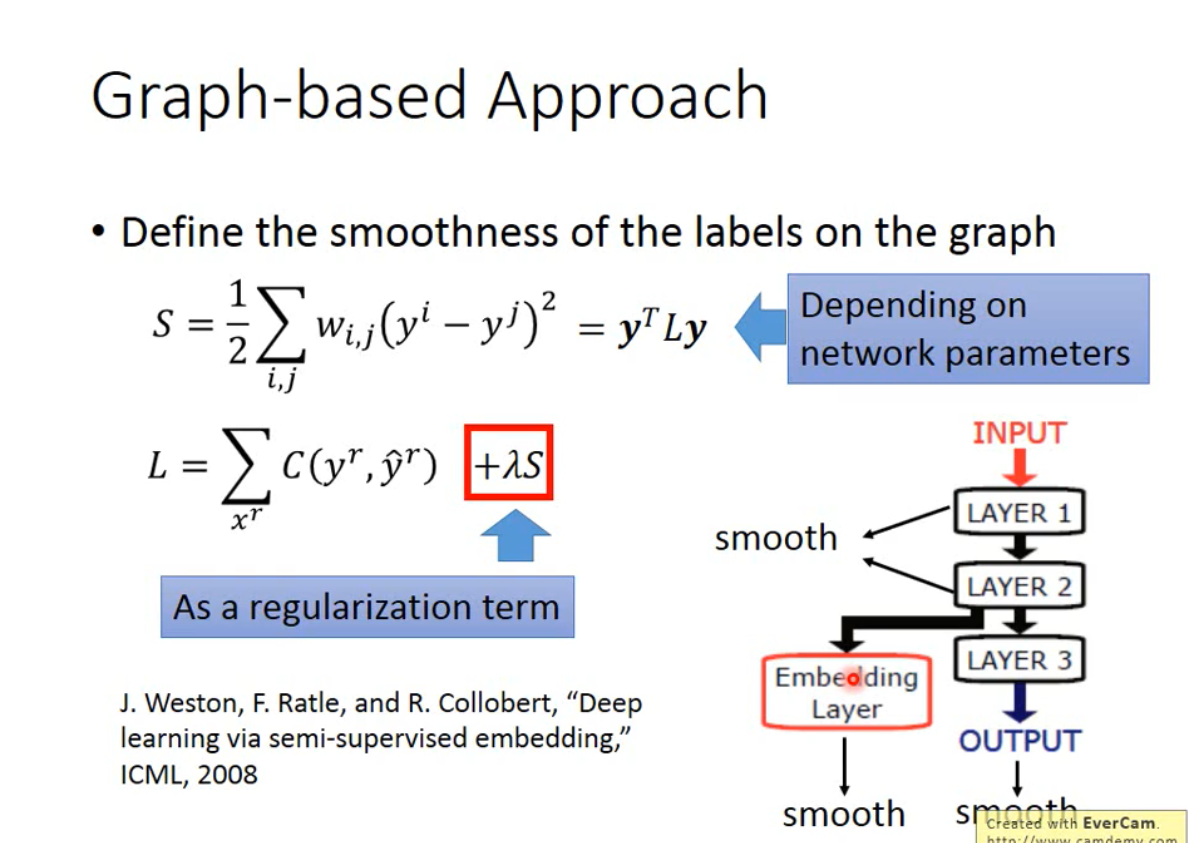
Better Representation
- 化繁为简
比较复杂的事物是由比较简单的事物操控,透过现象看到本质以后能进行更好的训练。